

Eenie Meenie Miney Mo
If you’ve stayed with me so far, you now hopefully have a solid understanding of function growth and asymptotic notation. But you still may be wondering how this is actually practical in the programming work you do every day. Being able to recognize and classify function growth will allow you to compare different algorithms to solve the same problem and identify which one is better. And as it is in the real world, when asked which algorithm is better, the answer is often “it depends.”
Scheduling Delima
For our first problem, let’s consider an event booking platform. Suppose we have a set of events that pertain to a particular venue, each with a start and end date. We want to write a function that will check to see if the venue is ever double booked. The element that can scale here is the number of events, so we’ll let the number of events be represented as n.
The naive approach:
public static bool HasConflicts(SchedulingEvent[] events)
{
foreach (SchedulingEvent evt1 in events)
{
foreach (SchedulingEvent evt2 in events)
{
if (evt1 != evt2 && evt1.Start < evt2.End && evt1.End > evt2.Start)
{
return true;
}
}
}
return false;
}
Something similar to the above would be a naive approach. For each event we’ll need to perform a comparison to every other event. In the worst case, there are no conflicts and the if statement will be evaluated exactly n^2 times. Therefore, this solution has a time complexity is O(n^2). But can we do better?
The sort and check approach:
public static bool HasConflicts(SchedulingEvent[] events)
{
SchedulingEvent[] orderedEvents = events
.OrderBy(evt => evt.Start)
.ToArray();
for (int i = 1; i < events.Length; i++)
{
if (orderedEvents[i].Start < orderedEvents[i - 1].End)
{
return true;
}
}
return false;
}
This algorithm is much more efficient. First, we sort the events by start time. Then we simply ensure that one event ends before the next event starts. Sorting the events is O(n lg n) and, in the worst case scenario, the if statement will by evaluated exactly n-1 times. Therefore, this algorithm has a time complexity of O(n lg n) + O(n) = O(n lg n).
For this problem, the second algorithm is the clear winner. But very often it’s not as simple as that.
Real Estate Notifications
Let’s suppose we have a real estate website where people can list their homes for sale. Every week, we email all of our subscribers a list of all the houses for sale in their postal code. For our analysis, let s be the number of subscribers and l be the number of listings.
The naive approach:
public static Email[] CreateEmails(Subscriber[] subscribers, Listing[] listings)
{
List<Email> emails = new List<Email>();
foreach (Subscriber subscriber in subscribers)
{
List<Listing> subscriberListings = new List<Listing>();
foreach (Listing listing in listings)
{
if (subscriber.PostalCode == listing.PostalCode)
{
subscriberListings.Add(listing);
}
}
if (subscriberListings.Any())
{
emails.Add(new Email(subscriber, subscriberListings.ToArray()));
}
}
return emails.ToArray();
}
This algorithm iterates through every listing for every subscriber. Therefore, the algorithm is Θ(s l).
The postal code hash approach:
public static Email[] CreateEmails(Subscriber[] subscribers, Listing[] listings)
{
Dictionary<string, Listing[]> dict = new Dictionary<string, Listing[]>();
foreach (string postalCode in GetAllPostalCodes())
{
List<Listing> postalCodeListings = new List<Listing>();
foreach (Listing listing in listings)
{
if (listing.PostalCode == postalCode)
{
postalCodeListings.Add(listing);
}
}
dict.Add(postalCode, postalCodeListings.ToArray());
}
List<Email> emails = new List<Email>();
foreach (Subscriber subscriber in subscribers)
{
Listing[] subscriberListings = dict[subscriber.PostalCode];
if (subscriberListings.Any())
{
emails.Add(new Email(subscriber, subscriberListings));
}
}
return emails.ToArray();
}
This algorithm takes a pessimistic approach. It essentially does all of the calculations for every postal code in the hopes that it will be able to reuse the calculations for subscribers in the same postal code. The algorithm iterates through every listing for every postal code. Then iterates through the subscribers. Therefore, the algorithm is Θ(p l + s) where p is the number of total postal codes.
Hmmm…. So which is better? Θ(sl) or Θ(pl + s)? This one’s not as easy to compare as the last one. First, we can realize that the number of postal codes is likely a constant value and we probably don’t have to worry about making sure our program will scale with the number of postal codes. In the US there are about 42,000 postal codes with a few new ones added from time to time. If you have to support international subscribers, you may have a higher number of postal codes (there are over 850,000 in Canada). For now, let’s assume there is a fixed 42,000 postal codes. Now, since postal codes are constant, the postal code hash approach is Θ(pl + s) which is significantly better than Θ(sl).
Now we know that as s and l grow very large, the second algorithm will be the clear winner. However, due to such a high constant, it’s not immediately clear when the second algorithm will outperform the first. One thing that we can tell right away is that if s is less than p, then the naive approach will always perform better because, in that case, sl will always be less than pl. We can see that the big advantage the hashing algorithm has is that it only has to add s, not multiply by it. This should be a hint to us that this algorithm will really shine when we scale for subscribers.
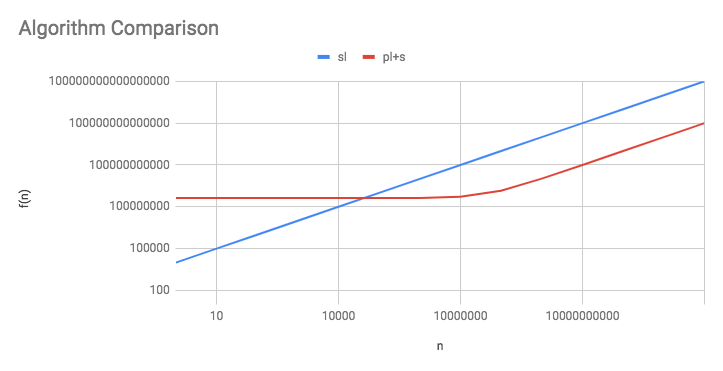
In this graph, both axes are shown on a logarithmic scale to make the data fit. We assumed that there were 1000 listings. Here we see that the naive algorithm starts out better, but shortly after the subscriber count surpasses the postal code count, the hash algorithm performs much better. In fact, we can solve for the exact value of s that would make the hash algorithm better.
sr = pr+s
rs - s = pr
(r-1)s = pr
s = pr/(r-1)
s = p (r/(r-1))
s = p ((r - 1 + 1)/(r-1))
s = p (1 + (1/r))
s = p + (1/r)p
So, the hash algorithm will be more efficient when the subscribers are greater than p and also slightly greater than r. Basically, if you have more than one listing, the hash algorithm will always be worse if you have fewer subscribers than postal codes and will always be better if you have more than twice as many subscribers as postal codes. So, if the site has 10,000 subscribers, you’re better off using the naive approach, but if the site has 1,000,000 subscribers, you’re better off using the hash approach. Specifically, in this example, the hash algorithm would win out somewhere between 40,000 and 80,000 subscribers depending on how many listings there were.
One step further
Let’s take this one step further. Let’s suppose that when we notify subscribers of listings, we don’t just notify them of listings in their postal code, but instead, we notify them of listings around their postal code. We let each subscriber set a distance limit preference between 1 - 100 miles. How does this change our analysis of the two algorithms? Well, both algorithms will have the same complexity, but the hash algorithm will have to do 100 times the number of calculations, one for each postal code and distance combination. Therefore, the hash algorithm will still be superior if the number of subscribers is large enough, but now the threshold is 4,000,000 subscribers instead of 40,000.
Note: These algorithms are just examples to illistrate these points. In reality, a hybrid of these two algorithms, one that uses memoization, would perform better.